耀世平台:一位 AI 画家的成长历程丨TECH TUESDAY
- 25
- 2023-03-29 12:55:15
- 298
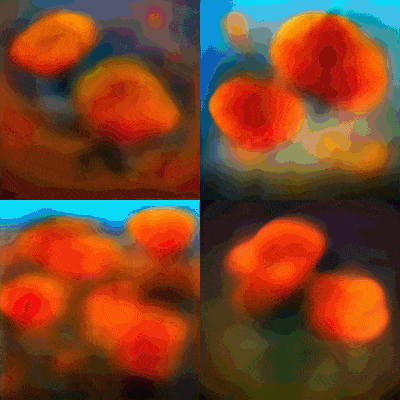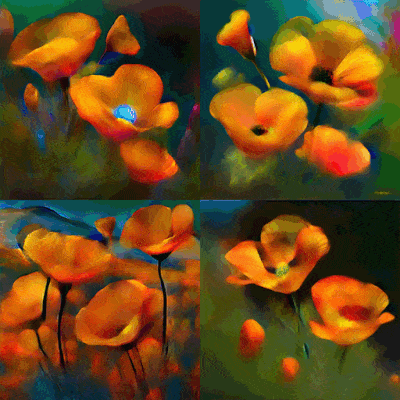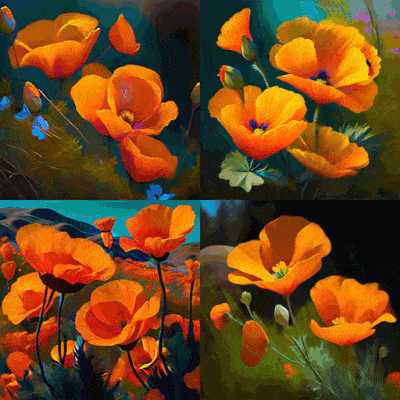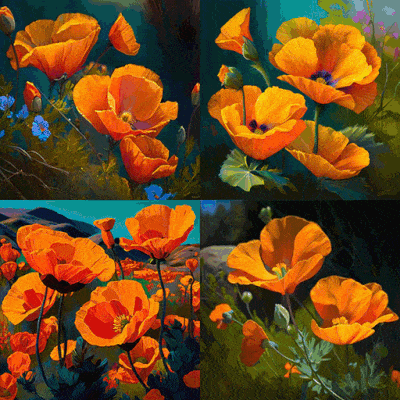
都是 AI 文生图,为何差别这么大。
文丨贺乾明
编辑丨龚方毅
在电脑上输入几个词,等着在屏幕上看到它们被转化成图片,比如山川湖海、鸟兽鱼虫、楼宇院落、人物肖像。不管效果如何,都不是容易的事。
因为实现这些前,需要解决计算机视觉和自然语言处理中那些最难的问题:电脑要学会听懂我们说的话,知道我们想表达什么,还要知道怎么把我们的话变成图画里的东西,最后还要尽可能好看。
这方面的产品化已经相对成熟,譬如 Stable Diffusion、Midjourney、OpenAI 旗下的 DALL·E 2,以及百度的文心一格。背后的实现算法也大同小异。
但上周文心一格画了一些让人难以理解的 “错图”。例如收到提示词 “起重机” 后画了一幅 “仙鹤”,或者把 “鼠标” 画成 “老鼠” 等。
百度用 177 字声明为其人工智能研发能力辩护,称是用 “符合行业惯例” 的全球互联网公开数据训练自研模型。它回应了有关 “抄袭”“套壳” 的质询,但没有说清楚为什么会出现这些错误。
机器画图是个听懂人话然后匹配图像的过程
当你在文本框里输入作图提示语(prompt),可以是几个词或一段话,用来形容你想要的作画主体、背景、风格、尺寸等,然后发给电脑。理论上提示语越精确,作图效果越惊艳。
系统接收到提示语以后,其背后一系列算法、模型便开始工作。第一步是理解人类语言,这得通过 “编码器” 把文字转化成一连串的数字、符号或字母,变成这套系统看得懂的语言。
因为已经提前学习了很多人画的东西,所以系统知道不同的东西长什么样子,对应什么样的文本。此时,它开始匹配最接近提示语特征的图像。比如猫有尖尖的耳朵,狗有长长的舌头,花有漂亮的颜色等。
接着它开始画图。先画出一张(或一组)很模糊的图片,有点像在雾里看东西一样。再过一会儿,画中主体的轮廓、色彩以及画作背景慢慢清晰。这是个不断地检查图片和文字是否匹配的过程,如果不匹配,它就会改变图片,让它更接近文字的意思。
最后,它可能会画出一张很清晰和漂亮的图片。
文生图应用生成图片的过程。图片来自 Midjourney。
这里的每一个环节都需要结合大量数据地反复训练。即便如此,机器也可能不理解提示语的含义,从而画出奇奇怪怪或者压根不合你意思的图片。
各家产品都依赖 Google 和 OpenAI 搭建的基础设施
这一轮人工智能根据文本提示语画图的爆发点,是 OpenAI 在 2022 年 4 月发布 DALL·E 2,它们展示了一系列新模型生成的作品,比如宇航员骑马、泰迪熊在时代广场上玩滑板,将现实世界中几乎不可能搭配在一起的元素巧妙地融合在一起。
教机器画图的尝试则更早启动。2015 年起,许多科学家试着通过一种称为 “对抗生成网络” 的技术,让电脑学习如何生成图片。其原理是用大量同类的图片,比如人脸,训练模型,让它学习一个人的面部都有什么特征,然后让一个模型负责生成人脸图片,另一个模型负责鉴定,符合要求后才算完成。
经过多年迭代,通过这种方法训练出来的图片已经以假乱真。但它局限也很明显,教它认识什么,就只会画什么 —— 用人脸数据训练,它只能随机生成人脸 —— 无法融入其它元素。
2017 年 Google 发布的 Transformer 架构极大程度地拔高了电脑理解文字的能力,后来成为诸多大语言模型的底层技术,如 OpenAI 的 ChatGPT、GPT-4 等。2020 年,Google 开始在图像处理领域试验 Transformer 架构,开启视觉领域的大模型研究。
借助 Google Transformer 架构的学习能力,OpenAI 在 2021 年带来文字生成图片领域的关键突破。它们训练了超过 4 亿个图文对,实证经过大量数据训练后人工智能模型,既可以根据文本提示较精确地找出图片,反过来它也能看懂图片。OpenAI 将这一研究成果取名 CLIP。
今天我们讨论的几乎所有文生图产品,包括 DALL·E 2(OpenAI 研发)、Midjourney、文心一格,要么直接用、要么借鉴 CLIP 的技术来理解语义和图像之间的关系,最后通过 “扩散模型” 生成图片。
如果把 “扩散” 想象成一种画画的方法,它是这样的:
- 首先,你在一张白纸上随便涂满一些颜色,这样就得到了一张全是噪声的图片。噪声就是一些没有意义的颜色点,看起来很乱。
- 然后,你开始用橡皮擦擦掉一些颜色,让图片变得稍微清晰一点。你要按照你想画的东西的形状和位置来擦,比如你想画一个苹果,就要在中间留下一个圆形。
- 接着,你继续用橡皮擦擦掉更多的颜色,让图片变得更清晰一点。你要按照你想画的东西的细节和特征来擦,比如你想画一个红色的苹果,就要在圆形里面留下红色。
- 最后,你重复这个过程很多次,直到你觉得图片已经很完美了。这样就完成了一张根据你想画的东西生成的图片。
训练数据质量和作图 “技法” 都很重要
机器从大量带有文字解释的图片中不断学习,才能较准确地把文本和图像关联起来,通常需要经过上亿甚至数十亿的 “图文对” 的训练。每一个产品化的文生图应用都经历了这一过程。
由于实现原理大同小异,区别不同产品的关键,成了训练大模型的数据质量和生成模型的调教策略。
百度文心一格的大模型 ERNIE-ViLG 公开于 2021 年,其模型训练的基础方法和同行近似,去年 10 月更新到了 2.0 版本。据其论文介绍,ERNIE-ViLG 训练数据集一共有 1.7 亿个图文对,其中一部分是百度的中文数据集,还有一部分是基于公开英文数据集的中译版(经百度机器翻译)。百度没有说明不同数据集的占比。
这就导致百度的大模型在没有上下文的情况下误判提示词的含义。比如 Mouse 既是鼠标也是老鼠,BUS 既是总线也是巴士, Musk 既是马斯克也是麝香。由于文心一格学习了大量的机翻英译中图文对,所以当接收到 “总线” 或者 “巴士” 的中文提示语,可能都会指向英文数据集中 “BUS” 对应的图片。
Midjourney 早期训练数据集和百度的一样,但前者既没有机器翻译造成的误差,同时自去年 11 月起即着手清理数据,删除其中模糊、带水印和边框的图片,以重新训练图像生成模型。
他们还花了大量资源和精力训练生成模型。Midjourney 创始人大卫·霍尔兹(David Holz)说,大多数团队只想让机器生成写实的图像,比如输入 “狗”,它会生成一张狗的图片,而他们自己想做的是 “弄清楚人们真正想要的是什么”,让机器学会什么样的图像有美感和创造力。
Midjourney 的进化。V2-V5 四个引擎下生成的“教皇打碟”(Papa Francesco DJ in a white jacket smiling)
为此 Midjourney 先花大量的时间给模型生成的图像评分反馈,持续调整模型,随着去年 7 月开放给普通用户,得以进一步借助用户反馈让模型学会审美。霍尔兹说 “随着时间的推移,用户的美感会融入系统”。
百度也在生成的环节投入了不少精力。根据他们发布的论文,百度的研究人员在生成图片时,针对不同的步骤,设置了不同的强化方式,尽可能提升生成效果。论文称在图像细节和质量方面的测试中,百度文心一格的模型,明显优于现有的模型,比如 DALL·E 2。
但对于人工智能应用来说,算法决定它的上限,而数据决定它离上限有多远。
一位百度人士称,他们已经开始清理数据、迭代模型。最新版本的文心一格已经分得清楚老鼠是老鼠,鼠标是鼠标。其他的产品也在飞速迭代,Midjourney 的最新版本基本攻克图像生成模型长期存在的问题 —— 画不出真实的手。
题图来自 Midjourney。本文得到了 ChatGPT 的协助。
发表评论